Как написать свой собственный интерпретатор на языке Си: подробный гайд
Содержимое
- 1 Как написать свой собственный интерпретатор на языке Си: подробный гайд
- 1.1 Инструкция по созданию интерпретатора на С: шаг за шагом для новичков
- 1.2 Видео по теме:
- 1.3 Сборка окружения и установка С
- 1.4 Основы языка С
- 1.5 Вопрос-ответ:
- 1.5.0.1 Что такое интерпретатор на языке C?
- 1.5.0.2 Для кого предназначена эта статья?
- 1.5.0.3 Какие принципы лежат в основе написания интерпретатора на языке C?
- 1.5.0.4 Какие библиотеки нужны для написания интерпретатора на языке C?
- 1.5.0.5 Какие языки можно проинтерпретировать с помощью этого руководства?
- 1.5.0.6 Какие задачи может решить написание интерпретатора на языке C?
- 1.5.0.7 Сколько времени потребуется для освоения материала этой статьи?
- 1.6 Подготовка рабочей среды для интерпретатора
- 1.7 Работа с файловой системой и пользовательским вводом
- 1.8 Пишем парсер
- 1.9 Создаем таблицу символов
- 1.10 Выполнение операций и вычисление выражений
- 1.11 Обработка условных выражений и циклов
- 1.12 Добавляем поддержку функций и их вызовов
- 1.13 Добавляем возможность создания глобальных переменных
- 1.14 Создание заголовочного файла и компиляция
В статье вы узнаете, как написать интерпретатор на языке Си. Мы предоставим подробные инструкции и примеры кода, которые помогут вам сделать это. Получите необходимые навыки и знания для создания своего собственного интерпретатора на Си.
C является одним из самых популярных языков программирования, и многие начинающие разработчики начинают свой путь именно с него. Но чуть менее распространена информация о том, что на языке С можно написать собственный интерпретатор.
В этой инструкции мы рассмотрим пошаговое создание своего интерпретатора на языке С. Мы будем следовать определенной структуре и использовать различные библиотеки и функции языка С. Конечный результат не только будет интересен для изучения, но и будет полезен в реальных приложениях.
Но прежде чем начать, давайте определимся, что такое интерпретатор и как он работает.
Инструкция по созданию интерпретатора на С: шаг за шагом для новичков
Создание своего интерпретатора на языке С — это сложный, но увлекательный процесс, даже для начинающих программистов. Это может быть интересным испытанием ваших знаний языка С и представлять собой отличную возможность понять, как работает интерпретатор.
Шаги, которые нужно выполнить для создания интерпретатора, включают в себя определение и запуск програмного кода. Сначала необходимо написать парсер, который будет считывать программу на языке С и формировать внутренней представление. Затем нужно создать интерпретатор, который проходит по внутреннему представлению и выполняет указанные в коде действия.
Создание интерпретатора на C начинается с написания модуля парсера. Этот модуль нужен для трансформации кода в подходящий вид для интерпретатора. Затем нам нужно имплементировать сам интерпретатор. Он будет получать выходные данные от парсера и решать, что делать с полученной информацией.
Помимо этого, вы должны создать структуру данных для представления языковых элементов. Она должна содержать различные объекты, такие как переменные, функции, операторы и т.д.
На этом этапе, вы должны были научиться создавать собственный интерпретатор на C. Следующий шаг — тестирование вашего интерпретатора на различных программных кодах. Дальше вы можете усовершенствовать ваш интерпретатор с добавлениями новых функций, например создание собственных операторов или функций. Обучение созданию вашего собственного интерпретатора на C может быть не простым, но потенциальный результат будет бесценен и даст вам незабываемый опыт программирования.
Видео по теме:
Сборка окружения и установка С

Прежде чем приступить к написанию интерпретатора на языке С, необходимо установить среду разработки. Для этого нужно выполнить несколько простых шагов:
- Скачайте и установите компилятор языка С для вашей операционной системы. Например, для Windows можно использовать MinGW (Minimalist GNU for Windows), для Linux — GCC (GNU Compiler Collection).
- Установите текстовый редактор или интегрированную среду разработки (IDE) для написания кода на языке С. Например, можно использовать Visual Studio Code, Atom, Code::Blocks, Dev-C++ и т.д.
- Настройте окружение для компиляции кода на языке С. В текстовом редакторе или IDE нужно указать путь до компилятора С и настроить параметры компиляции и запуска программы.
После выполнения этих шагов вы будете готовы к написанию интерпретатора на языке С. Не забывайте использовать лучшие практики программирования, такие как модульность, избегание глобальных переменных и проверку входных данных. Успехов в создании интерпретатора!
Основы языка С

Язык С – это высокоуровневый язык программирования, который был разработан в начале 1970-х годов в Bell Labs (США) и с тех пор стал одним из самых популярных языков в мире.
Для написания программ на языке С необходимо знать основные конструкции языка, такие как:
- переменные и их типы;
- операторы;
- функции и их параметры;
- управляющие конструкции (условные операторы, циклы);
- массивы и строки;
- указатели и динамическое выделение памяти.
Основная идея языка С заключается в том, что он предоставляет программисту полный контроль над компьютерными ресурсами, что может приводить к более эффективному использованию памяти и процессорного времени.
Знание языка С может быть полезным не только в написании интерпретаторов, но и во многих других областях программирования, таких как системное программирование, разработка драйверов, разработка игр и многих других.
Вопрос-ответ:
Что такое интерпретатор на языке C?
Интерпретатор на языке C — это программа, которая выполняет код на языке C построчно, без предварительной компиляции. Она считывает и анализирует код, переводит его в машинный язык и исполняет его.
Для кого предназначена эта статья?
Статья написана для начинающих программистов, которые хотят научиться создавать интерпретаторы на языке C. Она содержит пошаговую инструкцию, понятные примеры и объяснения основных концепций.
Какие принципы лежат в основе написания интерпретатора на языке C?
Основные принципы написания интерпретатора на языке C — это разбиение исходного текста на лексемы, грамматический анализ и построение AST (абстрактное синтаксическое дерево), выполнение команд построчно, обработка ошибок и управление состоянием программы.
Какие библиотеки нужны для написания интерпретатора на языке C?
Для написания интерпретатора на языке C необходимо использовать стандартные библиотеки языка, такие как stdio.h и string.h, а также библиотеку для работы с AST, например, libantlr3c.
Какие языки можно проинтерпретировать с помощью этого руководства?
С помощью этого руководства вы можете создавать интерпретаторы для любых языков программирования на базе текста, которые можно определить грамматикой и состоят из команд, которые можно выполнить построчно.
Какие задачи может решить написание интерпретатора на языке C?
Написание интерпретатора на языке C может решить множество задач, таких как обработка текстовых файлов, парсинг и анализ языков программирования, написание скриптов для автоматизации задач в операционных системах, создание игровых движков и многое другое.
Сколько времени потребуется для освоения материала этой статьи?
Для освоения материала этой статьи потребуется несколько недель или месяцев в зависимости от опыта программирования и объема проекта. Вам необходимо будет изучить базовый синтаксис языка C, принципы работы с библиотеками и научиться создавать AST и обрабатывать ошибки.
Подготовка рабочей среды для интерпретатора
Для написания интерпретатора на языке C необходимо подготовить рабочую среду, которая будет включать в себя несколько компонентов. В первую очередь нужно убедиться, что на вашем компьютере установлена среда разработки для языка C.
Для работы с интерпретатором на языке C вам необходимо также установить компилятор C, который будет использоваться для компиляции кода на языке С в исполняемый файл. Существуют различные компиляторы, например, GCC, Clang и Microsoft Visual C++.
Помимо среды разработки и компилятора С необходимо установить и настроить средства отладки, такие как gdb, для работы с интерпретатором. В случае необходимости вам понадобится также установить дополнительные библиотеки для работы с файлами и сетью.
- Установить среду разработки для языка С
- Установить компилятор С
- Настроить средства отладки
- Установить дополнительные библиотеки
После установки и настройки необходимых компонентов вы будете готовы начать написание интерпретатора на языке С. Не забывайте осуществлять регулярные проверки вашего кода на ошибки и отладку.
Работа с файловой системой и пользовательским вводом
При создании интерпретатора на языке С необходимо учитывать работу с файловой системой и пользовательским вводом. Эти функции позволят пользователям взаимодействовать с интерпретатором, загружать команды и данные для обработки.
Для работы с файловой системой в языке С используются стандартные библиотеки. Для открытия файла и чтения данных можно использовать функцию «fopen()». Для записи данных в файл можно использовать функцию «fwrite()».
Работа с пользовательским вводом также важна для создания интерпретатора. Чтобы пользователи могли вводить команды и данные, можно использовать функцию «fgets()». Она позволяет считывать данные из стандартного ввода, который может быть связан с клавиатурой.
Кроме того, при работе с пользовательским вводом необходимо иметь возможность обработки пользовательского ввода. Для этого можно использовать функцию «strcmp()». Она позволяет сравнивать введенные пользователем данные с определенными строками и выполнять соответствующие команды или действия.
Важно учитывать возможные ошибки при работе с файловой системой и вводом данных от пользователя. Для этого можно использовать блоки «try-catch», которые будут перехватывать ошибки и возвращать соответствующие сообщения.
В итоге, правильная работа с файловой системой и пользовательским вводом необходима для создания полноценного интерпретатора на языке С.
Пишем парсер

Написание парсера для интерпретатора является одним из самых важных этапов создания программы. Парсер должен уметь анализировать вводимые пользователем команды и определять, какую операцию нужно выполнить.
Существуют несколько подходов к написанию парсера, однако в основе большинства из них лежит использование грамматики языка, на котором написан интерпретатор. Грамматика задает правила синтаксиса языка и позволяет определить, какие команды может вводить пользователь и какие параметры они могут содержать.
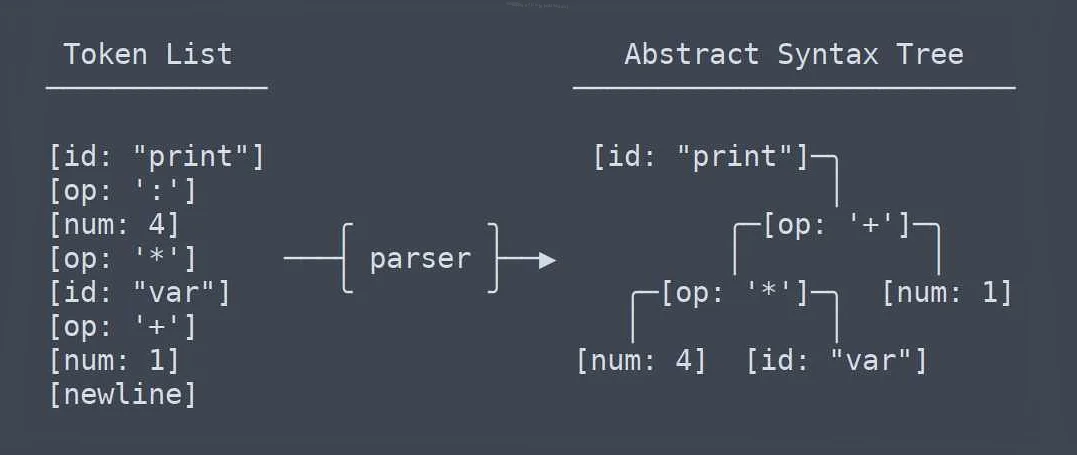
Для написания парсера можно использовать библиотеку flex, которая позволяет генерировать лексический анализатор. Лексический анализатор определяет лексемы в команде (например, команда «print» или число 10) и передает их в парсер.
Парсер может быть написан на языке yacc, который используется для генерации синтаксических анализаторов. Синтаксический анализатор принимает на вход лексемы и определяет правильность синтаксиса команды, а также создает дерево разбора, которое представляет собой структуру команды с указанием операций и их параметров.
В процессе написания парсера необходимо учитывать все возможные команды и их параметры, а также обрабатывать исключительные ситуации, такие как неправильный синтаксис команды или отсутствующие параметры. Хорошим подходом является создание тестовых наборов команд для проверки работоспособности парсера в различных условиях.
Создаем таблицу символов
Перед тем как начать работать над интерпретатором, необходимо создать таблицу символов. Таблица символов содержит информацию о различных идентификаторах, таких как названия переменных, ключевые слова, операторы и т.д.
Таблица символов может быть представлена в виде массива структур, каждая из которых содержит имя, тип данных, область видимости и прочие свойства. Эта таблица должна быть доступна во время выполнения программы для проверки семантических ошибок, например, использование необъявленных переменных.
Важно убедиться, что таблица символов содержит всю необходимую информацию, и организовать ее таким образом, чтобы было удобно получать доступ к данным в момент выполнения программы. При создании таблицы символов необходимо также учесть возможные конфликты имен и вести список зарезервированных слов, которые не могут быть использованы в качестве идентификаторов.
-
- Пример таблицы символов:
ИмяТипОбласть видимостиСвойства
| a | int | main() | |
| b | int | main() | |
| c | float | main() | |
| d | char | func() | static |
В данном примере таблица символов содержит имена переменных, их типы данных и области видимости. Также здесь приводится информация о свойствах переменных, например, ключевое слово «static».
Создание корректной таблицы символов — это важный шаг в написании интерпретатора, который позволяет проверять семантические ошибки во время выполнения программы.
Выполнение операций и вычисление выражений
В интерпретаторе на языке С выполнение операций и вычисление выражений являются ключевыми элементами. Ваш интерпретатор должен уметь распознавать различные математические операции и производить соответствующие вычисления.
Операции могут быть двух типов: унарные и бинарные. Унарные операции применяются к единственному операнду, например, отрицание. Бинарные операции, с другой стороны, требуют двух операндов, например, сложение.
В языке С доступны следующие бинарные операции: сложение (+), вычитание (-), умножение (*), деление (/) и модуль (%) — возвращает остаток от деления левого операнда на правый.
Кроме того, доступны унарные операции: операция инкремента (++), которая увеличивает значение операнда на 1, и операция декремента (—), которая уменьшает значение операнда на 1. Оба оператора можно записывать как префиксные (++x) или постфиксные (x++).
Для выполнения вычислений выражений вы можете использовать обратную польскую запись, также известную как постфиксную запись. При использовании постфиксной записи операнды выводятся перед операторами. Например, выражение «2 + 3» в постфиксной записи будет выглядеть как «2 3 +».
Для выполнения вычислений в постфиксной записи необходим стек, который вы можете реализовать с помощью динамического массива. При проходе по выражению каждый операнд добавляется в стек, а каждый оператор извлекается из стека и применяется к последним двум операндам в стеке. Результат операции затем помещается обратно в стек для дальнейшего использования.
Для экономии времени и написания более эффективного и простого кода вы можете использовать библиотеку math.h для выполнения математических операций, таких как возведение в степень, вычисление корня и тригонометрические функции.
Обработка условных выражений и циклов
В интерпретаторе, циклы и условные выражения выполняются с использованием стандартных структур языка C. Для написания условных выражений используются операторы if, else if и else. Они позволяют выполнять те или иные действия, если условие истинно или ложно.
Еще один способ обработки условных выражений — использование оператора switch. Этот оператор позволяет сравнивать значение переменной с множеством вариантов и обработать соответствующее условие.
Для написания циклов в языке C используется несколько операторов: for, while и do-while. Они позволяют выполнять повторяющиеся действия определенное количество раз или до тех пор, пока выполняется определенное условие.
Кроме того, в языке C есть операторы break и continue, которые позволяют контролировать выполнение циклов и выходить из них в нужный момент.
Использование условных выражений и циклов позволяет создавать мощные программы, которые могут выполнять различные задачи и обрабатывать большие объемы данных.
Добавляем поддержку функций и их вызовов
Чтобы добавить поддержку функций в наш интерпретатор, необходимо сначала изменить структуру нашего AST (Abstract Syntax Tree), чтобы он мог хранить информацию о функциях.
Мы можем добавить новый тип узла AST для функций, который будет содержать имя функции, список параметров и тело функции в виде другого AST.
Мы также должны добавить новый грамматический символ в нашу грамматику для объявления функций и позволить пользователю вызывать эти функции.
При парсинге нашего кода мы теперь будем строить AST, который будет содержать узлы для определения функций и вызовов функций.
При выполнении кода мы будем выполнять тела функций, когда они будут вызваны, и затем вернем результат обратно в вызывающую функцию, если это необходимо.
Таким образом, добавление поддержки функций в наш интерпретатор на С является важным шагом в создании полнофункционального языкового интерпретатора, который может обрабатывать более сложные программы.
Добавляем возможность создания глобальных переменных
Для того чтобы добавить поддержку глобальных переменных в наш интерпретатор на языке C, нужно сделать несколько шагов:
- Добавить функцию для хранения глобальных переменных.
- Обновить грамматику языка и добавить правила для создания и использования глобальных переменных.
- Добавить возможность вычисления и хранения значений глобальных переменных.
Создадим функцию для хранения глобальных переменных:
struct GlobalVarTable {
char* name;
int value;
}
Здесь мы создали структуру для хранения имени и значения глобальных переменных. Помимо этого, необходимо создать массив структур, где будут храниться все глобальные переменные:
struct GlobalVarTable globalVars[MAX_GLOBAL_VARS];
Далее, нужно обновить грамматику языка и добавить правила для создания и использования глобальных переменных:
declaration → type ID;
declaration → type ID = expression;
declaration → global_declaration
global_declaration → type ID = expression;
С помощью этих правил, мы можем объявлять глобальные переменные следующим образом:
int x = 0;
Далее, нужно добавить возможность вычисления и хранения значений глобальных переменных. Для этого нужно создать функцию, которая будет обрабатывать каждую новую глобальную переменную и добавить ее в массив структур:
void create_global_variable(char* name, int value) {
struct GlobalVarTable var;
var.name = name;
var.value = value;
globalVars[currentGlobalVar++] = var;
}
Теперь мы можем вызывать эту функцию для каждой новой глобальной переменной, устанавливая ее имя и значение. После этого мы сможем использовать ее в коде нашего интерпретатора.
Создание заголовочного файла и компиляция
Для начала работы над интерпретатором на языке C требуется создать заголовочный файл. Он содержит объявления функций и структур данных, которые будут использоваться в программе. В файле следует определить заголовки библиотек для работы с вводом-выводом, строками и динамической памятью.
Далее необходимо создать исходный файл программы. В этот файл помещаются реализации функций, прототипы которых объявлены в заголовочном файле. Важно следить за правильностью написания функций, чтобы программа могла успешно компилироваться.
После того, как заголовочный и исходный файлы готовы, необходимо произвести компиляцию. Этот процесс преобразует исходный код на языке C в исполняемый файл. Для компиляции можно воспользоваться стандартным компилятором GCC, который доступен в большинстве операционных систем.
Для компиляции следует использовать команду вида:
- gcc -o имя_исполняемого_файла исходный_файл.c — для компиляции исходного файла и создания исполняемого файла с указанным именем.
- gcc -c исходный_файл.c — для компиляции исходного файла с созданием объектного файла (.o), который затем можно будет связать с другими объектными файлами при создании исполняемого файла.
После успешной компиляции можно запустить полученный исполняемый файл и начать тестирование интерпретатора.



