Работа с библиотекой pandas в jupyter: руководство для начинающих
Содержимое
- 1 Работа с библиотекой pandas в jupyter: руководство для начинающих
- 1.1 Как использовать библиотеку pandas в Jupyter?
- 1.2 Установка и импорт библиотеки pandas
- 1.3 Создание и загрузка датафрейма в pandas
- 1.4 Работа с данными в датафрейме
- 1.5 Обработка пропущенных значений в pandas
- 1.6 Операции с группами и агрегация в pandas
- 1.7 Слияние нескольких датафреймов в pandas
- 1.8 Удаление дубликатов в pandas
- 1.9 Фильтрация и выборка данных в pandas
- 1.10 Изменение данных в датафрейме pandas
- 1.11 Видео по теме:
- 1.12 Вопрос-ответ:
- 1.13 Визуализация данных в pandas с помощью matplotlib
- 1.14 Советы и лучшие практики при работе с библиотекой pandas в Jupyter
Узнайте, как работать с библиотекой pandas в jupyter notebook. Научитесь пользоваться функциями, методами и основными инструментами для анализа и манипуляции с данными в Python.
В мире анализа данных чрезвычайно важно знать, как эффективно работать с библиотекой pandas. В исследовании больших обьемов данных и создании мощных аналитических инструментов, pandas является неотъемлемым инструментом. И сочетание его с Jupyter Notebook позволяет получать непревзойдённый инструмент манипуляции и визуализации данных.
В данной статье мы рассмотрим, как использовать pandas в Jupyter и рассмотрим лучшие практики и советы для эффективной работы с этими инструментами. Наша цель — помочь вам улучшить вашу экспертизу в анализе данных и не только создание красивых диаграмм и визуализаций, но и обработку данных в универсальных форматах.
Мы будем рассматривать базовые функции pandas, использование методов работы с дата-сетами в pandas и Jupyter, создание таблиц, обработка данных, а также предоставим вам некоторые советы по оптимизации вашего кода.
Как использовать библиотеку pandas в Jupyter?
Библиотека pandas — это мощный инструмент для работы с данными в Python, который позволяет обрабатывать, анализировать и визуализировать информацию. Если вы работаете с данными в Jupyter, то знание pandas — это необходимость.
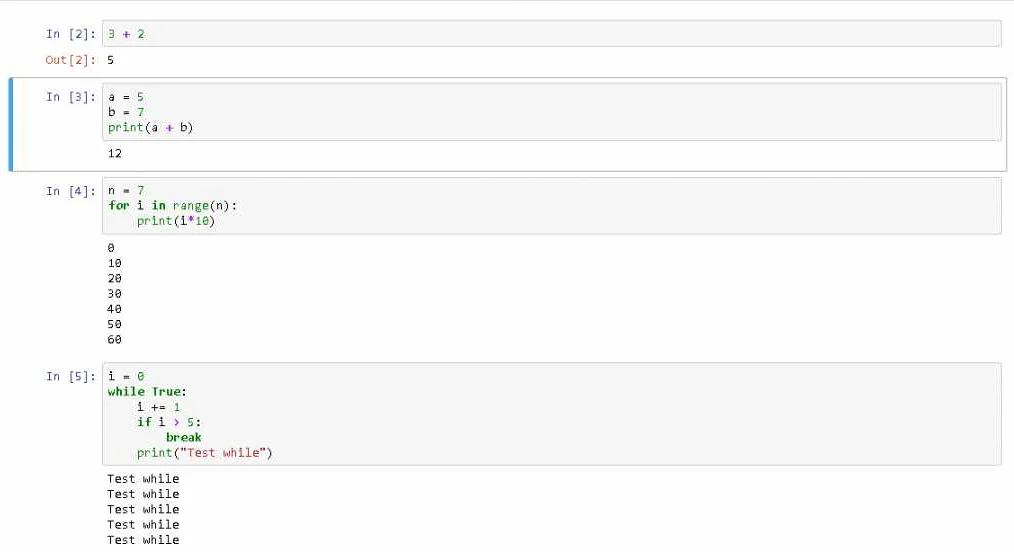
Чтобы начать работать с pandas, нужно импортировать его в свой проект:
import pandas as pd
Далее, вы можете создать объект DataFrame, который позволит вам работать с таблицами данных:
df = pd.DataFrame(data)
Где data — это ваш набор данных в виде словаря, списка или массива. DataFrame позволяет выполнять различные операции с данными, такие как выбор строк и столбцов, фильтрацию данных, группировку, сортировку и многое другое.
Одним из основных преимуществ pandas является возможность слияния и объединения данных из разных источников. Например, вы можете объединить два набора данных по общему столбцу:
merged_data = pd.merge(df1, df2, on=’column’)
Также, pandas позволяет проводить анализ данных и визуализацию. Вы можете создавать графики и диаграммы, используя библиотеку matplotlib:
import matplotlib.pyplot as plt
df.plot(kind=’line’)
В целом, pandas — это необходимый инструмент для работы с данными, особенно если вы работаете в Jupyter. Надеюсь, эти советы помогут вам использовать библиотеку pandas более эффективно.
Установка и импорт библиотеки pandas
Перед тем, как начать использовать библиотеку pandas, необходимо ее установить. Для этого можно воспользоваться менеджером пакетов pip, который уже установлен вместе с Python.
Для установки pandas нужно выполнить команду:
pip install pandas
После установки pandas, ее можно импортировать в Jupyter Notebook или другой Python-скрипт с помощью команды:
import pandas as pd
В данном случае мы импортируем библиотеку pandas и задаем ей псевдоним pd для удобства использования в дальнейшем.
Также можно импортировать отдельные модули из библиотеки pandas, например:
from pandas import DataFrame, Series
Эта команда импортирует только классы DataFrame и Series, которые могут быть полезны в конкретной задаче.
Прежде чем начать работу с pandas, необходимо установить и импортировать другие библиотеки, такие как NumPy и Matplotlib, которые необходимы для анализа данных и визуализации.
Например, можно использовать следующие команды для импорта библиотек NumPy и Matplotlib:
import numpy as np
import matplotlib.pyplot as plt
Создание и загрузка датафрейма в pandas
Для работы с pandas необходимо создать объект датафрейма. Его можно создать из различных источников, например, из файла CSV или Excel, из базы данных или просто создав его вручную.
Для загрузки данных из файла используется функция read_csv(), которая автоматически создает датафрейм на основе данных из CSV-файла. Например:
import pandas as pd
df = pd.read_csv(‘data.csv’)
Для загрузки данных из Excel-файла используется функция read_excel():
df = pd.read_excel(‘data.xlsx’)
Если нужно создать датафрейм вручную, то можно использовать функцию DataFrame(). Например, создадим датафрейм из нескольких списков:
data = {‘name’: [‘John’, ‘Mary’, ‘Peter’, ‘Paul’],
‘age’: [25, 36, 42, 28],
‘city’: [‘New York’, ‘Paris’, ‘London’, ‘Berlin’]}
df = pd.DataFrame(data)
Также можно создавать датафреймы из структурированных массивов, словарей и других структур данных.
Важно убедиться, что загруженные данные имеют правильный формат и не содержат ошибок. Для этого можно использовать функции
head() и tail(), которые позволяют просмотреть начало и конец датафрейма соответственно:
df.head()
df.tail()
Также можно использовать функцию info(), чтобы получить информацию о количестве строк и столбцов в датафрейме, а также типах данных в каждом столбце:
df.info()
Используя эти функции в процессе создания и загрузки датафрейма, можно гарантировать, что данные сформированы правильно и не содержат ошибок, что будет упрощать дальнейшую работу с датафреймом.
Работа с данными в датафрейме
Для эффективной работы с данными в библиотеке pandas необходимо уметь манипулировать датафреймом. Датафрейм – это таблица, которая состоит из строк и столбцов, где строки представляют отдельные записи, а столбцы – переменные, с которыми мы работаем. В датафрейме можно выполнять различные операции по фильтрации, агрегации, группировке и многому другому.
Одна из базовых операций – это выбор определенных данных из датафрейма. Для этого можно использовать методы iloc и loc, которые позволяют выбирать данные по номерам строк и столбцов, или по меткам индексов и столбцов. Например, чтобы выбрать первые 5 строк датафрейма, можно использовать метод df.iloc[:5,:], где df – это название датафрейма. А чтобы выбрать только определенные столбцы, можно использовать метод df[[‘column_name1’, ‘column_name2’, …]], где ‘column_name’ – название столбца.
Важной частью работы с данными является очистка данных от пропущенных значений и дубликатов. Для этого в pandas есть методы dropna() и drop_duplicates(), которые удаляют соответственно строки с пропущенными значениями и дубликаты записей. Также можно заменить пропущенные значения на средние или медианные значения, используя методы fillna() или interpolate().
Еще одна важная задача – это агрегация данных, то есть подсчет различных статистик по группам. Например, чтобы подсчитать средний возраст по группам пользователей, можно использовать методы groupby() и agg(). Группировка может осуществляться по одному или нескольким столбцам, и для каждой группы можно проводить агрегацию по различным статистикам – среднее, максимальное, минимальное и т.д.
Наконец, для визуализации данных в pandas можно использовать различные графики, такие как столбчатые диаграммы, круговые диаграммы, гистограммы и т.д. Для этого используются методы plot() и hist() с различными параметрами.
Обработка пропущенных значений в pandas
Пропущенные значения в данных — это распространенная проблема, с которой часто сталкиваются при анализе данных. В pandas есть несколько методов для работы с пропущенными значениями, которые помогают эффективно обрабатывать их.
Одним из наиболее используемых методов является метод fillna(), который позволяет заменить пропущенные значения на заданное значение или рассчитать новое значение с помощью определенной функции. Например, fillna(0) заменит все пропущенные значения на 0.
Еще одним методом является dropna(), который удаляет все строки или столбцы, содержащие хотя бы одно пропущенное значение. Если нужно выяснить, сколько пропущенных значений присутствует в данных, можно использовать метод isnull(), который возвращает булев массив той же формы, что и исходный DataFrame, с True для ячеек с пропущенными значениями.
Также в pandas есть возможность заполнения пропущенных значений на основе наиболее часто встречающихся значений в столбце с помощью метода fillna(mode()). Метод interpolate() используется для заполнения пропущенных значений путем интерполяции между соседними значениями.
Важно помнить, что при работе с пропущенными значениями нужно быть внимательным и анализировать данные, чтобы выбрать наиболее подходящий метод обработки пропущенных значений.
Операции с группами и агрегация в pandas
Pandas позволяет легко выполнять операции с группами данных, такие как группировка, агрегация, фильтрация и т.д. Группы могут быть сформированы на основе значения конкретного столбца или комбинации нескольких столбцов.
Для группировки данных в pandas используется метод groupby(). Это может быть полезно, например, для анализа продаж по регионам или для сравнения эффективности разных маркетинговых кампаний.
После группировки данных можно выполнять агрегатные функции, такие как count(), sum(), mean() и др. Агрегирующие функции помогают получить более подробную информацию о группах данных.
Например, можно найти сумму продаж по регионам или среднее время выполнения задач в рамках каждого проекта. Также можно использовать функции agg() и apply() для более сложных агрегаций данных.
После агрегации данных можно выполнять фильтрацию, сортировку или применять другие манипуляции с данными. Для удобства можно использовать цепочку методов, чтобы выполнить последовательность операций с данными.
При работе с группами данных в pandas можно также использовать функцию pivot_table(), которая позволяет создавать сводные таблицы и анализировать данные многомерно по нескольким измерениям.
В целом, операции с группами и агрегация данных в pandas очень удобны и мощны и позволяют быстро анализировать большие объемы данных. Важно только хорошо понимать возможности библиотеки и правильно применять ее функционал для получения нужных результатов.
Слияние нескольких датафреймов в pandas
Одной из самых важных возможностей библиотеки pandas является возможность объединения нескольких датафреймов. Часто бывает необходимо объединить два или более датафрейма, чтобы получить более полную информацию.
В pandas есть несколько способов объединения датафреймов: concat, merge и join.
concat объединяет несколько датафреймов вдоль указанной оси без выполнения каких-либо операций объединения. Этот способ наиболее прост в использовании, но он может потребовать дополнительной работы, если датафреймы имеют различные столбцы или индексы.
merge объединяет датафреймы на основе значений ключевых столбцов. Он очень гибкий, поскольку позволяет объединять датафреймы с разными индексами и столбцами. Тип объединения может быть выбран с помощью параметра how, который может принимать значения ‘left’, ‘right’, ‘outer’ и ‘inner’.
join — это синоним метода merge(), соответствующий объединению датафреймов по индексам. Он также позволяет указывать тип объединения с помощью параметра how.
Независимо от выбранного метода, перед объединением датафреймов необходимо удостовериться, что ключевые столбцы имеют одинаковые имена и типы данных. Рекомендуется также провести проверку на наличие дубликатов и некорректных данных.
Примером использования метода merge() может быть объединение двух датафреймов по столбцу ‘customer_id’:
customer_idnamecity
| 101 | John Smith | New York |
| 102 | Jane Doe | Los Angeles |
customer_idorder_id
| 101 | 1001 |
| 102 | 1002 |
Сначала необходимо выполнить импорт библиотеки pandas:
import pandas as pd
Далее можно объединить датафреймы с помощью метода merge():
df = pd.merge(df1, df2, on=’customer_id’)
Результатом будет датафрейм, содержащий информацию о клиентах и их заказах:
customer_idnamecityorder_id
| 101 | John Smith | New York | 1001 |
| 102 | Jane Doe | Los Angeles | 1002 |
Удаление дубликатов в pandas
Дубликаты в данных могут привести к ошибкам и искажению результатов анализа. Pandas предоставляет функционал для удаления дубликатов.
Для удаления дубликатов используется метод drop_duplicates(). В качестве аргументов метода можно указать столбцы, по которым нужно искать дубликаты. По умолчанию метод ищет дубликаты по всем столбцам.
Если в датафрейме много столбцов и необходимо задать критерии уникальности только для части столбцов, можно использовать аргумент subset. Например, df.drop_duplicates(subset=[‘column1’, ‘column2’]).
Также можно настроить метод на сохранение первого или последнего встреченного дубликата, используя аргумент keep. Например, для сохранения первого встреченного дубликата используется значение keep=’first’.
Метод drop_duplicates() возвращает новый датафрейм без дубликатов. Однако можно и изменить исходный датафрейм, передав аргумент inplace=True.
Использование метода drop_duplicates() — важный шаг в предобработке данных, который поможет избежать проблем в процессе анализа и получить точные результаты.
Фильтрация и выборка данных в pandas
Одной из ключевых возможностей библиотеки pandas является возможность фильтрации и выборки данных из больших датафреймов. Для этого можно использовать методы .loc и .iloc.
Метод .loc используется для выборки по меткам (названиям) строк и столбцов. Например, чтобы выбрать все данные по конкретным меткам строк и столбцов, можно использовать следующий синтаксис:
df.loc[[‘метка_строки_1’, ‘метка_строки_2’], [‘метка_столбца_1’, ‘метка_столбца_2’]]
Метод .iloc используется для выборки по номерам строк и столбцов. Например, чтобы выбрать все данные по конкретным номерам строк и столбцов, можно использовать следующий синтаксис:
df.iloc[[номер_строки_1, номер_строки_2], [номер_столбца_1, номер_столбца_2]]
Также можно использовать логические операторы для фильтрации данных. Например, чтобы выбрать все строки, у которых значение в определенном столбце больше заданного значения, можно использовать следующий синтаксис:
df[df[‘название_столбца’] > значение]
Также можно комбинировать логические операторы. Например, чтобы выбрать строки, у которых значение в столбце ‘столбец_1’ меньше значения ‘значение_1’ И значение в столбце ‘столбец_2’ больше значения ‘значение_2’, можно использовать следующий синтаксис:
df[(df[‘столбец_1’] < значение_1) & (df[‘столбец_2’] > значение_2)]
Очень часто возникает необходимость отфильтровать строки, которые содержат определенный текст в определенном столбце. Для этого можно использовать метод str.contains(). Например, чтобы выбрать все строки, которые содержат слово «apple» в столбце ‘product’, можно использовать следующий синтаксис:
df[df[‘product’].str.contains(«apple»)]
Изменение данных в датафрейме pandas
Один из главных компонентов работы с библиотекой pandas — это возможность изменять данные в датафреймах. Для этого нужно понимать, как работать с индексами, выбирать нужные строки и столбцы данных, а также как применять функции для изменения содержания датафрейма.
В первую очередь, можно изменять значения в ячейках датафрейма. Для этого нужно использовать метод at или loc, указав индекс строки и столбца, в которых нужно изменить значение.
-
- Метод at работает быстрее, если изменяется только одна ячейка. Примеры кода по использованию метода at:
df.at[3, ‘column’] = ‘new_value’ # изменить значение в строке 3 и столбце ‘column’ на ‘new_value’
-
- Метод loc более универсален и можно использовать для изменения нескольких ячеек сразу. Примеры кода по использованию метода loc:
df.loc[3, ‘column’] = ‘new_value’ # изменить значение в строке 3 и столбце ‘column’ на ‘new_value’
df.loc[3:5, ‘column_1′:’column_3’] = ‘new_value’ # изменить значения в строках 3-5 и столбцах ‘column_1’-‘column_3’ на ‘new_value’
Кроме изменения значений в отдельных ячейках, также можно изменять данные целых столбцов или строк. Для этого можно использовать срезы данных или фильтрацию.
-
- Для изменения значения целого столбца нужно присвоить ему новое значение:
df[‘column’] = ‘new_value’
-
- Для изменения значения целой строки нужно использовать метод loc:
df.loc[3] = [‘new_value_1’, ‘new_value_2’, ‘new_value_3’, …]
-
- Для изменения части данных датафрейма можно использовать срезы данных:
df.loc[3:5, ‘column_1′:’column_3’] = ‘new_value’
-
- Для изменения данных по условию можно использовать фильтрацию:
df.loc[df[‘column’] == ‘value’, ‘column’] = ‘new_value’
Важно помнить, что при изменении данных в датафрейме нужно делать это аккуратно и не забывать сохранять изменения, если они нужны в дальнейшей работе.
Видео по теме:
Вопрос-ответ:
Что такое библиотека pandas и зачем она нужна в Jupyter?
Библиотека pandas — это библиотека для анализа данных в Python, предоставляющая возможности для работы с табличными данными, временными рядами и многомерными данными. В Jupyter библиотека pandas полезна для быстрой загрузки, обработки и анализа данных прямо из тетради, а также для визуализации и представления результатов анализа в виде графиков.
Визуализация данных в pandas с помощью matplotlib
У библиотеки pandas есть встроенная интеграция с библиотекой визуализации данных matplotlib. Это означает, что вы можете использовать функции pandas для создания графиков без необходимости знакомиться с matplotlib.
Одним из преимуществ использования библиотеки pandas для визуализации данных является ее удобство. Вы можете легко создавать графики, используя стандартные методы pandas, такие как plot() и hist(). Эти методы позволяют создавать графики как с одной, так и с несколькими переменными.
Для создания графика с помощью метода plot() вы можете использовать следующий синтаксис:
dataframe.plot(x=’column’, y=’column’, kind=’plot_type’)
Где dataframe — это данные, которые вы хотите визуализировать, column — это столбцы в данных, которые вы хотите использовать для создания графика, а plot_type — это тип графика, который вы хотите создать.
Если вы хотите создать гистограмму с помощью метода hist(), вы можете использовать следующий синтаксис:
dataframe.hist(column=’column’)
Где dataframe — это данные, которые вы хотите визуализировать, а column — это столбец в данных, который вы хотите использовать для создания гистограммы.
Использование библиотеки pandas для визуализации данных может сэкономить время и упростить процесс создания графиков. Это позволяет работать с данными более эффективно и точно определять тенденции и закономерности в данных.
Советы и лучшие практики при работе с библиотекой pandas в Jupyter
1. Используйте методы для просмотра данных: head(), tail(), info(), describe(), чтобы быстро получить информацию о структуре и содержании датафрейма.
2. Создавайте новые столбцы на основе существующих данных, используя методы pandas, такие как: apply(), lambda функции и смешанные операции.
3. Используйте специальные инструменты pandas для работы с датами и временем, чтобы быстро и эффективно анализировать временные ряды.
4. Используйте инструменты для группировки данных, такие как: groupby(), pivot_table(), чтобы провести анализ данных и исследовать связи между различными переменными.
5. Используйте индексы и мультииндексы, чтобы быстро и эффективно навигировать по датафрейму и быстро находить нужные объекты.
6. Используйте методы для обработки пропущенных данных, такие как: dropna(), fillna(), чтобы обрабатывать недостающие данные и избегать ошибок в анализе.
7. Используйте методы pandas для объединения данных, такие как: merge(), concat(), чтобы объединять данные из разных источников и создавать новые датафреймы.
8. Используйте методы для экспорта и импорта данных, такие как: to_csv(), read_csv() и другие форматы, чтобы обмениваться данными со сторонними приложениями и сохранять результаты анализа.



