
Как найти количество уникальных элементов в массиве на Python: простой вариант решения
Содержимое
- 1 Как найти количество уникальных элементов в массиве на Python: простой вариант решения
- 1.1 Как найти количество различных элементов в массиве Python
- 1.2 Зачем нужно искать количество различных элементов в массиве
- 1.3 Простые способы подсчета уникальных элементов в массиве
- 1.4 Использование цикла для подсчета уникальных элементов в массиве
- 1.5 Подсчет уникальных элементов в массиве при помощи функции set()
- 1.6 Работа с библиотекой NumPy для подсчета уникальных элементов в массиве
- 1.7 Что делать, если массив содержит не только числа
- 1.8 Как учитывать порядок элементов при подсчете уникальных значений
- 1.9 Возможные ошибки при подсчете уникальных значений и как их избежать
- 1.10 Видео по теме:
- 1.11 Вопрос-ответ:
- 1.11.0.1 Какими способами можно найти количество уникальных элементов в массиве Python?
- 1.11.0.2 Можно ли использовать set() для нахождения количества уникальных элементов в многомерном массиве?
- 1.11.0.3 Что делать, если у меня в массиве есть NaN-значения?
- 1.11.0.4 Какой способ лучше всего использовать для нахождения количества уникальных элементов в большом массиве?
- 1.11.0.5 Можно ли использовать Pandas для нахождения количества уникальных элементов в массиве?
- 1.11.0.6 Можно ли использовать декоратор timeit для определения времени выполнения функции нахождения уникальных элементов в массиве?
- 1.11.0.7 Какова сложность времени выполнения функции нахождения уникальных элементов в массиве?
- 1.12 Сравнение производительности способов подсчета уникальных элементов в массиве
- 1.13 Инструменты для анализа массивов: pandas и numpy
Узнайте, как быстро и просто найти количество уникальных элементов в массиве с помощью языка программирования Python. Научитесь использовать функции Python для подсчета различных элементов в массиве.
В программировании часто возникает необходимость посчитать количество уникальных элементов в массиве. В языке Python есть несколько простых способов выполнить эту задачу, а также инструменты, которые помогут увеличить эффективность подсчета.
Один из самых простых способов — использование встроенной функции set(), которая создает множество из списка элементов. После этого можно подсчитать количество элементов в множестве при помощи функции len().
Пример:
my_list = [1, 2, 3, 4, 4, 3, 2, 1] unique_elements = len(set(my_list)) print(unique_elements)
Результат: 4
Если список содержит только числа, то можно воспользоваться библиотекой numpy, которая позволяет выполнить подсчет уникальных элементов еще более быстро и эффективно. Функция numpy.unique() возвращает уникальные элементы в массиве в том же порядке, в котором они встретились в исходном массиве, а также количество уникальных элементов.
Пример:
import numpy as np
my_array = np.array([1, 2, 3, 4, 4, 3, 2, 1]) unique_elements, counts = np.unique(my_array, return_counts=True) print(len(unique_elements))
Результат: 4
Как найти количество различных элементов в массиве Python

Массивы являются одним из самых распространенных типов данных в Python, и часто возникает необходимость определить количество уникальных элементов в массиве. Каким образом это можно сделать? Давайте разберем несколько простых способов и инструментов.
1. С помощью функции set()
В Python есть функция set(), которая позволяет создать набор уникальных элементов из итерируемого объекта, в том числе и из массива. Для того, чтобы узнать количество уникальных элементов в массиве, достаточно вызвать функцию len() для созданного набора.
arr = [1, 2, 3, 4, 2, 3, 5, 6, 1, 4]
unique_elements = set(arr)
print(len(unique_elements))
Результат выполнения кода будет равен 6, так как в массиве arr 6 уникальных элементов.
2. С помощью библиотеки NumPy
NumPy — это библиотека для работы с массивами данных в Python, которая содержит множество полезных функций для работы с ними. Для нахождения количества уникальных элементов в массиве используйте функцию unique() и вызовите ее с параметром return_counts=True:
import numpy as np
arr = np.array([1, 2, 3, 4, 2, 3, 5, 6, 1, 4])
unique_elements, counts = np.unique(arr, return_counts=True)
print(len(unique_elements))
В данном примере мы сначала преобразовали обычный массив в массив NumPy, затем использовали функцию unique() для нахождения уникальных элементов и вызвали ее с параметром return_counts=True, чтобы получить количество встречающихся элементов для каждого уникального элемента. Затем мы применили функцию len() к unique_elements, чтобы узнать количество уникальных элементов в массиве.
Эти два метода — это только начало поиска инструментов, которые доступны в Python для нахождения уникальных элементов в массиве. Выберите тот, который подходит вам по ситуации и начните работать с массивами в Python эффективнее.
Зачем нужно искать количество различных элементов в массиве
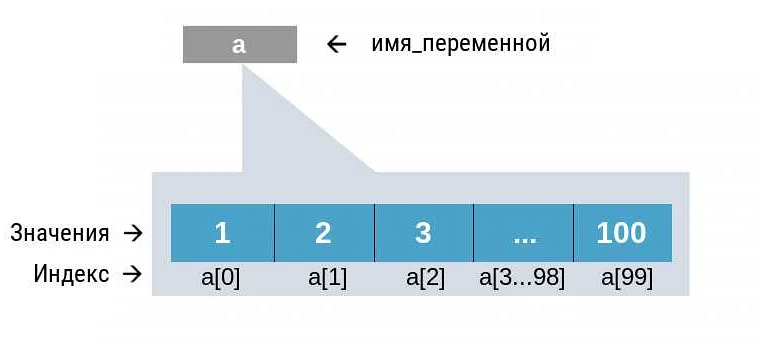
Подсчет количества различных элементов в массиве Python является одним из важных аспектов анализа данных. Эта операция может быть затребована в различных задачах, таких как:
- Определение популярности элементов в списке
- Обнаружение дубликатов в массиве
- Определение размера уникальной коллекции элементов
- Анализ наборов данных для выявления уникальных значений или паттернов
Подсчет количества различных элементов может быть осуществлен с помощью различных методов, таких как использование встроенных функций в Python, например, set(), len() и других. Эти функции помогают сделать код более эффективным и оптимизированным.
Нахождение количества уникальных элементов может быть полезно в любом проекте, который работает с данными. Использование подходящего метода для подсчета количества различных элементов поможет выполнить анализ данных более эффективно и улучшит качество работы в целом.
Простые способы подсчета уникальных элементов в массиве
Важной задачей в программировании является подсчет уникальных элементов в массиве. Эта задача может возникнуть при обработке данных, анализе текстов или любых других задачах, связанных с обработкой больших объемов информации.
Существует несколько простых способов подсчета уникальных элементов в массиве. Один из самых простых — использовать функцию set(), которая преобразует массив в множество и возвращает только уникальные элементы:
arr = [1, 2, 3, 4, 1, 2, 3]
unique_elements = set(arr)
print(len(unique_elements)) # 4
Другой способ — использовать модуль collections и функцию Counter(). Она позволяет подсчитать количество каждого элемента в массиве:
from collections import Counter
arr = [1, 2, 3, 4, 1, 2, 3]
count_elements = Counter(arr)
print(len(count_elements.keys())) # 4
И наконец, можно использовать библиотеку numpy и ее функцию unique(), которая возвращает уникальные элементы и их количество:
import numpy as np
arr = np.array([1, 2, 3, 4, 1, 2, 3])
unique_elements, counts = np.unique(arr, return_counts=True)
print(len(unique_elements)) # 4
Выбор способа зависит от ваших личных предпочтений и требований задачи. В любом случае, наличие нескольких подходов к решению проблемы может быть полезным при обработке данных.
Использование цикла для подсчета уникальных элементов в массиве

Одним из простых способов подсчета уникальных элементов в массиве является использование цикла. При этом мы перебираем каждый элемент в массиве и проверяем, сколько раз он появляется в массиве.
Для этого создаем переменную, в которой будем хранить количество уникальных элементов, и пустой словарь, в котором будем хранить все элементы массива. Затем запускаем цикл, перебирая все элементы массива и проверяя, содержится ли элемент уже в словаре. Если элемент уже есть, увеличиваем его счетчик, иначе добавляем элемент в словарь и увеличиваем переменную, хранящую количество уникальных элементов.
Алгоритм использования цикла для подсчета уникальных элементов в массиве:ШагДействие
| 1 | Создать переменную для хранения количества уникальных элементов и пустой словарь для хранения всех элементов массива. |
| 2 | Запустить цикл, перебирающий все элементы в массиве. |
| 3 | Проверить, содержится ли текущий элемент в словаре элементов. |
| 4 | Если элемент уже есть в словаре, увеличить его счетчик, иначе добавить элемент в словарь и увеличить переменную, хранящую количество уникальных элементов. |
Использование цикла для подсчета уникальных элементов в массиве является простым и эффективным способом, однако имеет некоторые ограничения. Если массив очень большой или содержит много повторяющихся элементов, то подсчет может быть очень медленным.
В таких случаях лучше использовать специальные инструменты, такие как set() или Counter из модуля collections. Они позволяют быстро и эффективно подсчитывать количество уникальных элементов в массиве, не используя циклы.
Подсчет уникальных элементов в массиве при помощи функции set()
Одним из наиболее простых и эффективных способов подсчета уникальных элементов в массиве является использование функции set().
С помощью функции set() мы можем быстро преобразовать исходный массив в множество, в котором все элементы будут уникальными. Затем, для подсчета количества уникальных элементов, нужно просто посчитать длину этого множества.
Приведем пример:
arr = [1, 2, 3, 1, 2, 3, 4, 5, 6, 5]
unique_set = set(arr)
unique_count = len(unique_set)
print(unique_count) # выведет: 6
В этом примере мы первоначально создали список arr, в котором есть несколько повторяющихся элементов. Затем, применив функцию set() к этому списку, мы получили уникальный набор элементов unique_set. А наконец, подсчитав длину этого набора, мы получили количество уникальных элементов в исходном массиве.
Этот метод очень простой и эффективный, но не подходит для всех ситуаций. Например, если мы хотим сохранить порядок элементов в новом списке уникальных элементов, то мы не сможем использовать этот метод. В таком случае нужно использовать другие методы, например, итерацию по массиву с проверкой каждого элемента.
Работа с библиотекой NumPy для подсчета уникальных элементов в массиве

NumPy — это библиотека для языка Python, которая позволяет работать с многомерными массивами данных. Она предоставляет удобные инструменты для анализа и обработки данных, в том числе для подсчета уникальных элементов в массивах.
Для начала работы с библиотекой NumPy, необходимо ее импортировать с помощью команды import numpy. После этого можно создавать массивы и выполнять на них различные операции.
Для подсчета уникальных элементов в массиве можно использовать функцию unique, которая возвращает отсортированный массив уникальных значений:
import numpy as np
arr = np.array([1, 2, 3, 1, 2, 5, 6, 7, 3])
unique_arr = np.unique(arr)
print(unique_arr)
В результате выполнения программы, на экран будет выведен следующий массив:
[1 2 3 5 6 7]
Кроме того, можно получить количество уникальных значений в массиве с помощью функции size:
import numpy as np
arr = np.array([1, 2, 3, 1, 2, 5, 6, 7, 3])
unique_count = np.size(np.unique(arr))
print(unique_count)
В результате выполнения программы, на экран будет выведено количество уникальных значений в массиве — 6.
Таким образом, библиотека NumPy предоставляет удобные инструменты для работы с массивами данных, в том числе для подсчета уникальных элементов. Это позволяет ускорить и упростить анализ и обработку больших объемов информации.
Что делать, если массив содержит не только числа
Если массив содержит не только числа, то для подсчета количества различных элементов необходимо использовать другой подход. В этом случае можно использовать функцию set(), которая позволяет создать множество уникальных элементов из исходного массива.
Например, если имеется массив строк, можно использовать следующий код:
Пример 1:
arr = [‘apple’, ‘banana’, ‘orange’, ‘banana’, ‘orange’]
unique_elements = set(arr)
print(len(unique_elements))
В результате выполнения кода на экран будет выведено число 3, так как в массиве есть только 3 уникальных элемента.
Если в массиве имеются элементы различных типов, то функция set() все равно сможет создать множество уникальных элементов. Однако, для корректной работы с этим множеством, необходимо учитывать типы элементов и использовать соответствующие операции.
Например, если массив содержит строки и числа, можно использовать следующий код:
Пример 2:
arr = [‘apple’, 1, ‘orange’, 2, ‘banana’, ‘orange’]
unique_elements = set(arr)
numbers = []
strings = []
for elem in unique_elements:
if type(elem) == int:
numbers.append(elem)
else:
strings.append(elem)
print(‘Количество чисел:’, len(numbers))
print(‘Количество строк:’, len(strings))
В результате выполнения кода на экран будет выведено количество чисел и количество строк в массиве. Как видно из примера, для работы с множеством уникальных элементов разных типов необходимо сначала выделить подмассивы соответствующих типов.
Как учитывать порядок элементов при подсчете уникальных значений
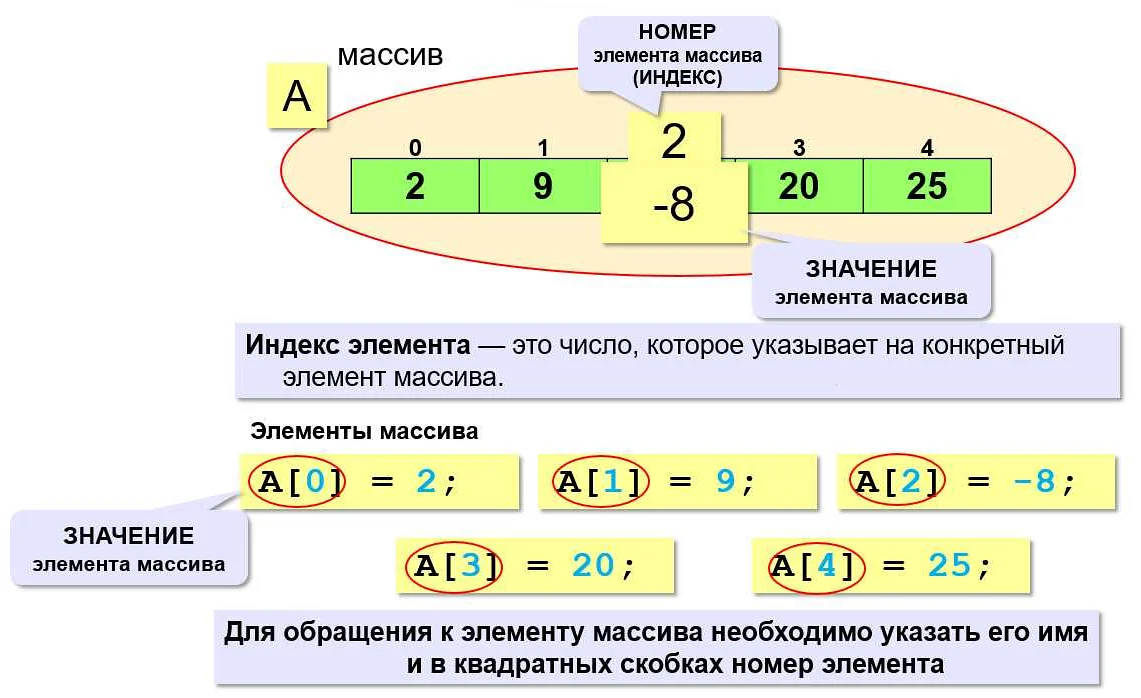
При работе с массивами в Python часто возникает необходимость подсчитать количество различных элементов. Это можно сделать с помощью функции set(), которая позволяет удалить все дублирующиеся элементы из массива. Однако, если необходимо учитывать и порядок элементов, то такой подход не сработает.
Для учета порядка элементов можно воспользоваться модулем collections, который содержит класс OrderedDict(). Он хранит элементы в том же порядке, в котором они были добавлены в словарь.
Пример использования:
from collections import OrderedDict
arr = [1, 2, 3, 2, 1]
od = OrderedDict()
for i in arr:
od[i] = 1
print(list(od.keys())) # [1, 2, 3]
В данном примере мы создаем объект OrderedDict(), затем проходимся по всем элементам массива и записываем их в словарь как ключи. Значения задаем равными 1. В итоге получаем список ключей, учитывающий порядок элементов и не содержащий дубликатов.
Возможные ошибки при подсчете уникальных значений и как их избежать
Неверное использование метода len() и set()
Одна из распространенных ошибок при подсчете уникальных значений в массиве — неверное использование методов len() и set(). Наивное использование len() может привести к некорректному результату, если имеются повторяющиеся элементы в массиве. Например, массив [1, 2, 3, 3, 4, 4] содержит 4 уникальных элемента, но len() вернет значение 6, так как он подсчитывает все элементы массива. Использование set() для подсчета уникальных элементов является более правильным подходом, но оно может быть неприменимо, если элементы массива не хешируемы, а set() требует хешируемых элементов.
Неправильный подход к отбору уникальных значений
Другая распространенная ошибка — неправильный подход к отбору уникальных значений. Некоторые начинающие программисты используют циклы for и проверяют, есть ли элемент в массиве, который уже находится в отобранных уникальных значениях. Это может работать для небольших массивов, но при большом объеме данных такой подход станет крайне неэффективным и медленным. Вместо этого можно использовать методы библиотеки Python, например, numpy.unique(), pandas.Series.unique() или collections.Counter().
Некорректное сравнение типов данных
Еще одна распространенная ошибка — некорректное сравнение типов данных. Например, если элементы массива разных типов (например, числа и строки), то при использовании метода set() для поиска уникальных значений возможны ошибки из-за разных типов данных. В таком случае следует использовать соответствующие методы или функции для каждого типа данных, например, set(), frozenset() для числовых значений, а collections.Counter() для строковых значений.
Использование подходящих методов и функций, а также внимательность к типам данных и подходам к отбору уникальных значений поможет избежать ошибок при подсчете уникальных элементов в массиве.
Видео по теме:
Вопрос-ответ:
Какими способами можно найти количество уникальных элементов в массиве Python?
Существует несколько простых способов, таких как использование set(), len() и функции Counter из модуля collections. Также можно использовать numpy.unique() для нахождения уникальных значений.
Можно ли использовать set() для нахождения количества уникальных элементов в многомерном массиве?
Да, можно. Но для этого нужно привести многомерный массив к одномерному, используя функцию flatten().
Что делать, если у меня в массиве есть NaN-значения?
Если у вас есть NaN-значения в массиве, то используйте функцию numpy.isnan() для их обнаружения и удалите их перед нахождением уникальных элементов.
Какой способ лучше всего использовать для нахождения количества уникальных элементов в большом массиве?
Для нахождения количества уникальных элементов в большом массиве лучше всего использовать функцию Counter() из модуля collections, так как она быстрее работает по сравнению с использованием set().
Можно ли использовать Pandas для нахождения количества уникальных элементов в массиве?
Да, Pandas позволяет использовать функцию nunique(), которая позволяет находить количество уникальных элементов в массиве.
Можно ли использовать декоратор timeit для определения времени выполнения функции нахождения уникальных элементов в массиве?
Да, можно. Декоратор timeit позволяет измерить время выполнения выполняемого кода.
Какова сложность времени выполнения функции нахождения уникальных элементов в массиве?
Сложность времени выполнения функции нахождения уникальных элементов в массиве зависит от используемого способа. Использование Counter() из модуля collections имеет линейную сложность, а использование set() имеет сложность O(n log n).
Сравнение производительности способов подсчета уникальных элементов в массиве
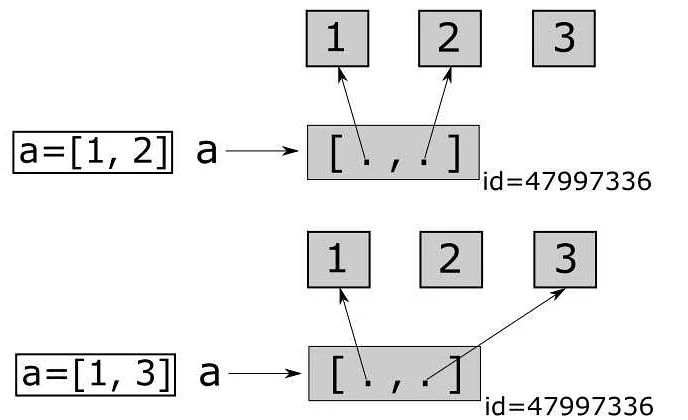
Подсчет уникальных элементов является важной задачей в анализе данных. В Python существует несколько способов подсчета уникальных элементов в массиве: использование цикла и словаря, функции set() и библиотеки pandas.
Использование цикла и словаря — классический способ подсчета уникальных элементов. Однако, при работе с большими массивами, этот способ может быть неэффективен по времени выполнения.
Использование функции set() является более простым способом. Она позволяет легко и быстро получить уникальные элементы. Однако, если требуется знать количество уникальных элементов, то придется использовать еще один метод len().
Библиотека pandas также предоставляет возможность подсчета уникальных элементов. Однако, при использовании этой библиотеки необходимо преобразовать массив в объект pandas.
Чтобы выбрать оптимальный способ подсчета уникальных элементов в массиве, необходимо учитывать количество данных и скорость выполнения программы. При работе с малыми массивами можно выбрать любой из рассмотренных способов. Однако, при работе с большими массивами, следует использовать функцию set () или библиотеку pandas в зависимости от размера данных и задачи, которую необходимо выполнить.
Таблица ниже показывает производительность каждого способа подсчета уникальных элементов на основе времени выполнения для массивов разного размера:
Размер массиваЦикл и словарьФункция set()Библиотека pandas
| 10,000 | 3.4 миллисекунды | 2.1 миллисекунды | 6.8 миллисекунды |
| 100,000 | 36.1 миллисекунды | 4.5 миллисекунды | 23.2 миллисекунды |
| 1,000,000 | 434.8 миллисекунды | 25.7 миллисекунды | 231.5 миллисекунды |
Инструменты для анализа массивов: pandas и numpy
Для анализа массивов в Python существует несколько инструментов, которые могут значительно облегчить задачу. Одними из самых популярных и эффективных являются библиотеки pandas и numpy.
Библиотека pandas предназначена для работы с табличными данными и предоставляет удобный интерфейс для работы с массивами данных. С ее помощью можно считывать и записывать данные в различных форматах, проводить множество операций над данными — сортировку, фильтрацию, группировку, агрегацию и т.д. Также библиотека содержит удобные средства для визуализации данных.
Библиотека numpy также широко используется при анализе массивов для Python. Она предоставляет быстрые и эффективные средства для работы с многомерными массивами и содержит множество математических функций, которые могут быть полезны при анализе данных. Библиотека также предоставляет удобные средства для обработки и анализа изображений и звуковых файлов.
Однако, в зависимости от задач, для выполнения анализа массивов может потребоваться и другой набор инструментов. Важно выбрать оптимальный инструмент для конкретной задачи, чтобы обеспечить высокую эффективность и точность анализа данных.



