
Как правильно считать список из файла в Python: простой гайд для начинающих
Содержимое
- 1 Как правильно считать список из файла в Python: простой гайд для начинающих
- 1.1 Основные понятия
- 1.2 Подготовка файла с данными
- 1.3 Открытие файла
- 1.4 Чтение данных из файла
- 1.5 Обработка данных
- 1.6 Закрытие файла
- 1.7 Использование контекстного менеджера with
- 1.8 Работа с различными форматами данных
- 1.9 Обработка ошибок
- 1.10 Оптимизация работы с файлами
- 1.11 Вопрос-ответ:
- 1.11.0.1 Зачем нужно считывать списки из файлов в Python?
- 1.11.0.2 Каковы основные методы чтения списков из файлов в Python?
- 1.11.0.3 В чем разница между функциями readline() и readlines() при считывании списков из файлов?
- 1.11.0.4 Как считывать списки из CSV-файлов в Python?
- 1.11.0.5 Как обработать ошибки при чтении списка из файла в Python?
- 1.11.0.6 Можно ли изменять списки, считываемые из файла в Python?
- 1.11.0.7 Какой формат файла наиболее удобен для считывания списков в Python?
- 1.12 Практические примеры
- 1.13 Видео по теме:
Узнайте, как правильно считать список из файла на языке Python. Ознакомьтесь с примерами кода и научитесь использовать различные методы чтения файлов для получения данных.
Одной из наиболее частых задач при работе с Python является считывание списка из файла. Не всегда это задание просто для новичков, особенно если речь идет о больших списках. В этой статье мы рассмотрим полезные советы, которые помогут вам правильно считать список из файла в Python и избежать возможных ошибок и проблем.
Считывание списка из файла в Python может быть нужно в разных случаях. Например, при работе с таблицами данных или различными списками и массивами. Хорошая новость состоит в том, что Python предлагает несколько способов для считывания списка из файла, в том числе и более оптимальных.
В этой статье мы разберемся, как правильно использовать эти методы и дадим вам некоторые советы по работе с большими списками, чтобы считывание данных проходило без проблем и эффективно.
Основные понятия
В программировании на языке Python считывание списка из файла – один из базовых приемов обработки данных. Для того, чтобы правильно считать список, необходимо понимать основные понятия:
- Файл – набор данных, записанных на внешнем носителе, хранящийся под уникальным идентификатором (именем файла).
- Путь к файлу – параметр, указывающий на местонахождение файла в файловой системе операционной системы.
- Открытие файла – процесс подключения программы к файлу, с целью чтения или записи данных.
- Режим открытия файла – параметр, указывающий на то, как файл будет обрабатываться: для чтения, записи или в виде потока данных.
- Чтение файла – процесс считывания данных из файла и передачи их в память программы.
- Список – структура данных, предназначенная для хранения упорядоченной последовательности элементов. В Python список представляется в квадратных скобках и может содержать любые типы данных.
Эти основные понятия необходимы для того, чтобы правильно считать список из файла в языке Python и обработать его дальше по необходимости.
Подготовка файла с данными

Прежде, чем начинать работу с файлами данных в Python, нужно правильно их подготовить. Если вы хотите считать данные из текстового файла, необходимо убедиться, что файл создан в правильном формате и не содержит ошибок.
Перед тем, как создать файл с данными, определитесь с форматом файла, который будет использоваться. Например, Вы можете использовать CSV-файлы, чтобы хранить табличные данные, разделяя значения запятыми. Если вы хотите хранить текстовые данные, то простой текстовый файл вполне подойдет.
Однако, обратите внимание на кодировку файла. В настоящее время наиболее распространенной кодировкой является UTF-8, которая поддерживает множество языков и символов.
Также рекомендуется проверить файл на наличие ошибок. Это можно сделать с помощью специальных инструментов, доступных в Python, например, можно воспользоваться модулем codecs.
Не забывайте сохранять файлы в безопасном месте и установите права доступа к файлу в соответствии с вашими потребностями. Храните файлы форматированными и хорошо структурированными, чтобы избежать ошибок при считывании и использовании данных.
Открытие файла
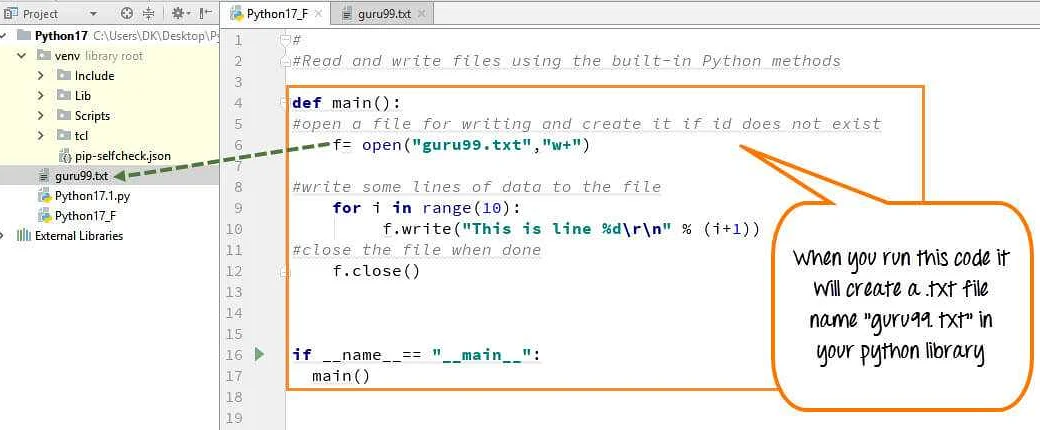
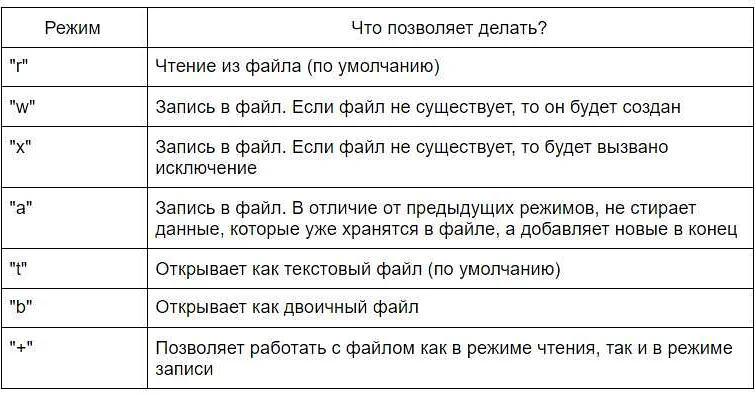
В Python для работы с файлами используется функция open(), которая позволяет открыть файл указанного имени и режима. Режим открытия файла может быть задан вторым параметром функции:
- «r» — режим чтения файла (по умолчанию);
- «w» — режим записи, файл будет создан (или перезаписан, если он существует);
- «x» — режим эксклюзивного создания файла (файл не должен существовать);
- «a» — режим добавления данных в конец файла;
- «b» — режим работы с бинарным файлом (например, изображением);
- «t» — режим работы с текстовым файлом (по умолчанию).
Функция open() возвращает объект, представляющий открытый файл, который можно использовать для чтения или записи данных.
Например, чтобы открыть файл «data.txt» для чтения, можно использовать следующий код:
file = open(«data.txt», «r»)
После окончания работы с файлом необходимо его закрыть, для этого используется метод close() объекта файла:
file.close()
Рекомендуется всегда закрывать файл после окончания работы с ним, чтобы не было потери данных.
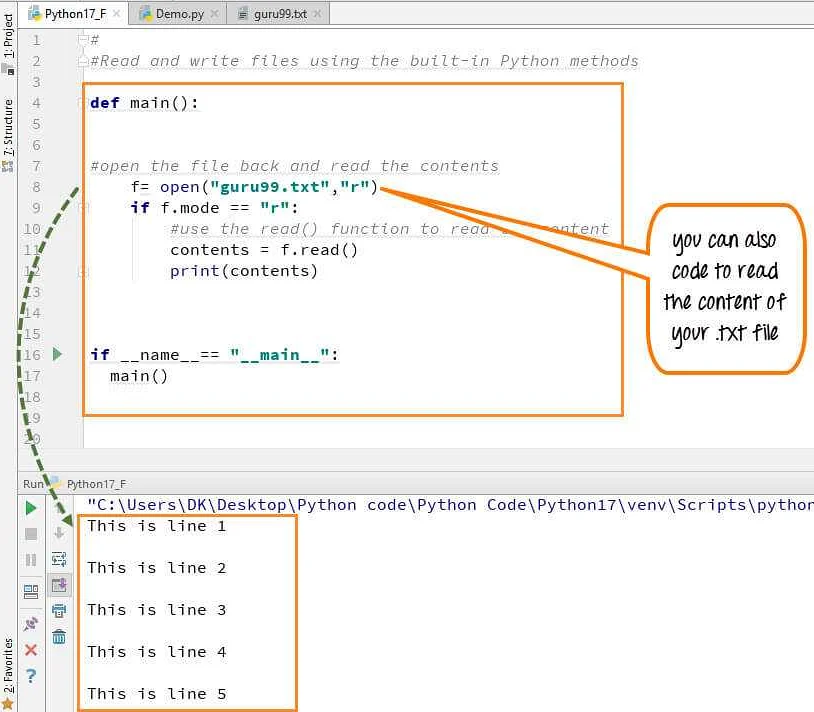
Чтение данных из файла

Одним из базовых навыков программирования является работа с файлами. В Python для чтения данных из файла используется функция open(), которая открывает файл в нужном режиме.
Вот как выглядит общий синтаксис функции:
f = open(«filename.txt», «r»)
В этом примере мы открываем файл с именем «filename.txt» и режимом «r» (чтение). Если файл существует, то функция откроет его, иначе будет выброшено исключение.
Читать данные из файла можно с помощью методов объекта файла:
- read() – чтение всего файла целиком
- readline() – чтение одной строки
- readlines() – чтение всех строк и сохранение их в списке
Пример чтения файла с помощью метода readlines():
f = open(«filename.txt», «r»)
lines = f.readlines()
for line in lines:
print(line)
f.close()
В этом коде мы открываем файл «filename.txt» в режиме «r», читаем все строки файла с помощью метода readlines(), сохраняем их в список с именем lines, и затем выводим каждую строку в консоль с помощью цикла for. Не забудьте закрыть файл после окончания работы с ним.
Также можно использовать конструкцию with open(), которая автоматически закрывает файл после выполнения всего блока кода. Вот пример использования:
with open(«filename.txt», «r») as f:
lines = f.readlines()
for line in lines:
print(line)
В этом коде мы открываем файл «filename.txt» в режиме «r» с помощью конструкции with open(), читаем все строки с помощью метода readlines(), сохраняем их в список lines и выводим каждую строку в консоль с помощью цикла for. После выполнения всего блока кода файл «filename.txt» будет автоматически закрыт.
Обработка данных
Обработка данных – это один из самых важных этапов в программировании. Это процесс, который позволяет обрабатывать, преобразовывать и анализировать данные, полученные в программе. В Python, существует множество инструментов, которые помогают обрабатывать данные, а также задавать их формат и структуру.
Один из основных инструментов для обработки данных является модуль pandas. С помощью этого модуля можно читать и записывать данные в форматах CSV, Excel, SQL и многие другие, а также проводить многие операции с данными, включая фильтрацию, сортировку, агрегирование, группирование и объединение.
Для работы с текстовыми данными в Python можно использовать модуль re. Он предоставляет мощные средства для работы с регулярными выражениями, которые позволяют выполнять множество задач, связанных с поиском, заменой и форматированием текстовых данных.
Для работы с числовыми данными в Python часто используется модуль NumPy. Он предоставляет средства для работы с массивами и матрицами, а также многие функции для проведения операций над числами.
В Python также есть многие другие инструменты и библиотеки для обработки данных, включая модуль datetime для работы с датами и временем, библиотеку Matplotlib для визуализации данных, библиотеку Scikit-learn для машинного обучения и многие другие.
Важно понимать, что обработка данных является основным этапом в любой программе, и для успешного выполнения этой задачи необходимо изучить различные инструменты и методы обработки данных в Python.
Закрытие файла
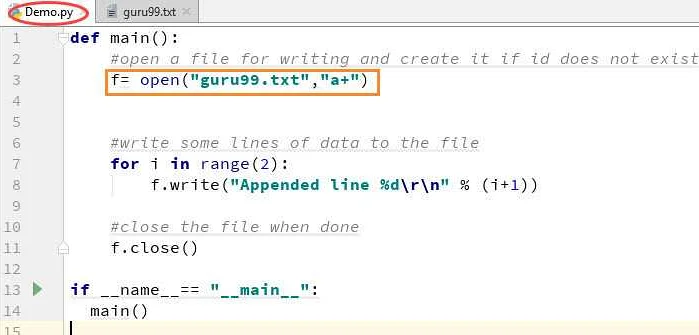
Закрытие файла — очень важный аспект работы с файлами в Python. Как уже было сказано, при открытии файла операционная система выделяет для него ресурсы, которые должны быть освобождены после завершения работы с файлом. Закрытие файла позволяет избежать утечки ресурсов и других возможных проблем.
В Python закрыть файл можно, вызвав метод close() объекта файла.
Вот как это выглядит:
file.close()
Лучше всего всегда аккуратно освобождать ресурсы, и закрывать файлы немедленно после окончания работы с ними. Если вы случайно забыли закрыть файл, Python, в зависимости от версии и операционной системы, может выдавать ошибку или крашить программу.
Также можно использовать менеджер контекста with, который автоматически закрывает файл после завершения блока кода. Вот пример использования менеджера контекста:
with open(‘file.txt’, ‘r’) as file:
for line in file:
# some operation
В этом случае, после завершения блока кода, файл автоматически закроется.
Использование контекстного менеджера with
В языке программирования Python есть своего рода интерфейс, позволяющий автоматически открывать и закрывать файлы во время его использования. Этот интерфейс называется контекстным менеджером with.
Использование контекстного менеджера with — это один из наиболее надежных и безопасных способов открытия файла для работы в Python. Файл автоматически закрывается после того, как блок with завершился, даже если внутри блока с файлом произошла ошибка.
Чтобы использовать контекстный менеджер with для чтения файла в Python, нужно указать имя файла и режим доступа (например, «r» для чтения). После этого вы можете начать читать файл внутри блока with, который будет автоматически закрыт по завершении.
Пример использования контекстного менеджера with:
-
- Открыть файл:
with open(‘file.txt’, ‘r’) as f:
-
- Прочитать строки файла и присвоить переменной:
file_data = f.read()
-
- Закрыть файл:
f.close()
Как видите, контекстный менеджер with в Python делает работу с файлами более удобной и безопасной. Он гарантирует, что файл будет закрыт надлежащим образом, даже если внутри блока произойдет ошибка.
Работа с различными форматами данных

При работе с Python можно столкнуться с большим количеством различных форматов данных, которые нужно считывать и обрабатывать. Некоторые из них включают в себя:
- Текстовые файлы
- CSV-файлы
- JSON-файлы
- XML-файлы
- SQL-базы данных
Каждый из этих форматов имеет свои особенности и методы работы. Например, для считывания текстового файла необходимо использовать стандартные функции Python, такие как open() и read().
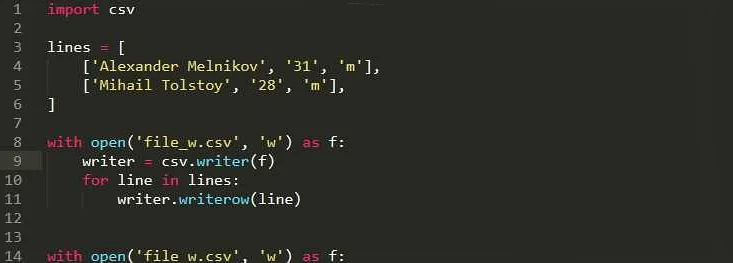
CSV-файлы используются для хранения табличных данных, где каждая строка представляет отдельное значение, разделенное символом запятой. Для работы с CSV-файлами в Python можно использовать библиотеку csv, которая предоставляет удобные методы для чтения и записи файлов.
JSON-файлы широко используются при работе с веб-приложениями, так как это формат данных, который удобно передавать через сеть. Для работы с JSON-файлами в Python можно использовать встроенный модуль json.
XML-файлы также используются при работе с веб-приложениями и могут содержать сложные структуры данных. Для работы с XML-файлами в Python можно использовать модули ElementTree и lxml.
SQL-базы данных используются для хранения больших объемов данных, которые могут быть легко считаны и отфильтрованы. Для работы с такими базами данных в Python можно использовать библиотеку SQLite или SQLAlchemy.
Важно понимать, что каждый формат данных имеет свои преимущества и недостатки, и необходимо выбирать тот, который лучше всего подходит для конкретных задач. Также важно уметь читать и обрабатывать данные в различных форматах, чтобы эффективно выполнять свою работу.
Обработка ошибок
При работе с файлами в Python необходимо учитывать возможность возникновения ошибок на разных этапах выполнения программы: от открытия файла до чтения или записи данных. Необработанные ошибки могут привести к непредсказуемым результатам или даже к ошибкам и завершению программы.
Поэтому для обеспечения корректной работы программы рекомендуется использовать механизмы обработки ошибок при работе с файлами. В Python для этого предназначены конструкции try/except/finally.
При чтении списка из файла в Python, необходимо учитывать возможность исключительных ситуаций, таких как: отсутствие файла, ошибки чтения данных, некорректное форматирование данных в файле и другие. Для устранения ошибок в коде, необходимо использовать соответствующие блоки try/except/finally, которые будут обрабатывать исключения и предотвращать завершение программы.
При разработке программного кода, необходимо также учитывать возможность ошибок, которые могут возникнуть в результате некорректных или неполных данных, поступающих на вход программы. В этом случае также рекомендуется использовать соответствующие блоки try/except/finally, а также обрабатывать исключительные ситуации.
- Краткие рекомендации по обработке ошибок:
- Использовать конструкции try/except/finally для обработки ошибок;
- Учитывать возможность исключительных ситуаций на всех этапах работы программы;
- Предусмотреть обработку исключений, связанных с открытием и чтением файла;
- Обрабатывать исключения при работе с данными на вход программе на основе заданных требований.
Оптимизация работы с файлами
Работа с файлами в Python — это важная задача, которую нужно выполнять правильно и эффективно. В этой статье мы расскажем о некоторых методах оптимизации работы с файлами, которые помогут вам сократить время выполнения программы.
1. Используйте контекстный менеджер
Контекстный менеджер в Python позволяет управлять открытием и закрытием файлов автоматически. Это значит, что вам не нужно самому отслеживать открытие и закрытие файла, что может сэкономить много времени и уменьшить вероятность ошибок.
2. Используйте метод readlines()
Если вы хотите считать все строки из файла, то вместо цикла for можно использовать метод readlines(). Он считывает все строки в список, что может заметно ускорить процесс чтения файла.
3. Используйте генераторы
Генераторы — это мощный инструмент, который может помочь оптимизировать работу с файлами. Они позволяют читать файл построчно и обрабатывать строки по мере их поступления. В отличие от метода readlines(), генераторы не загружают все строки в память, что может быть полезным при работе с большими файлами.
4. Используйте буферизацию
Буферизация в Python позволяет читать файлы блоками, что ускоряет процесс чтения и записи файла. Для этого нужно открыть файл с использованием буферизации:
- Для чтения: open(‘file.txt’, ‘r’, buffering=1024)
- Для записи: open(‘file.txt’, ‘w’, buffering=1024)
5. Используйте модуль multiprocessing
Модуль multiprocessing позволяет выполнять операции параллельно, что может сократить время работы программы. Если вы читаете большой файл, вы можете разбить его на несколько частей и обработать каждую часть в отдельном процессе. Это позволит использовать все ядра процессора и ускорить процесс чтения файла.
Номер строкиСодержимое строки
| 1 | Куртка 1 |
| 2 | Куртка 2 |
| 3 | Куртка 3 |
Вопрос-ответ:
Зачем нужно считывать списки из файлов в Python?
Считывание списков из файлов может быть полезно в различных задачах программирования, например, при обработке больших объемов данных или при работе с результатами предыдущих расчетов. Это также может помочь в автоматизации рабочих процессов и избежании ручного ввода больших объемов информации.
Каковы основные методы чтения списков из файлов в Python?
В Python существует несколько способов считывания списков из файлов, включая использование функций readline() и readlines(), а также модуля csv. Каждый метод имеет свои преимущества и недостатки, и выбор зависит от конкретного случая использования.
В чем разница между функциями readline() и readlines() при считывании списков из файлов?
Функция readline() считывает одну строку файла за один раз, в то время как функция readlines() считывает все строки и возвращает список строк. Если файл содержит только один список, то можно использовать функцию readlines(). Если в файле несколько списков, то в цикле с помощью функции readline() можно считывать строки и формировать список по мере необходимости.
Как считывать списки из CSV-файлов в Python?
Модуль csv в Python предоставляет инструменты для работы с CSV-файлами. Для считывания списка из CSV-файла можно использовать класс csv.reader(). Этот класс предоставляет метод next() для чтения каждой строки файла в виде списка значений, который может быть добавлен в список всех строк. После завершения чтения файла список строк можно преобразовать для получения итогового списка.
Как обработать ошибки при чтении списка из файла в Python?
При чтении списка из файла в Python может возникнуть несколько ошибок, таких как FileNotFoundError или ValueError. Чтобы обработать эти ошибки, можно использовать оператор try-except, который позволяет производить проверки и выполнение дополнительных действий при возникновении ошибок.
Можно ли изменять списки, считываемые из файла в Python?
Да, это возможно. После считывания списка из файла в Python, список хранится в памяти в качестве объекта списка. Этот объект можно изменять, добавлять, удалять элементы и т. д. Если требуется сохранить изменения списка, его можно записать в файл с помощью функции write() или модуля csv.
Какой формат файла наиболее удобен для считывания списков в Python?
Формат файла для считывания списков в Python может быть различным, в зависимости от требований конкретного проекта. Однако, для простоты реализации и работы с данными, наиболее удобным форматом является текстовый файл, в котором каждый список находится в отдельной строке и разделен запятыми или другим символом.
Практические примеры

Давайте рассмотрим несколько примеров того, как правильно считывать список из файла в Python:
Пример 1:
-
- Создайте файл «example.txt» с содержимым:
- apple
- banana
- orange
- Напишите следующий код, чтобы считать этот список из файла:with open(«example.txt», «r») as file:lines = file.read().splitlines()
print(lines)
- Запустите код и вы получите следующий вывод:
- Создайте файл «example.txt» с содержимым:
[‘apple’, ‘banana’, ‘orange’]
Пример 2:
-
- Создайте файл «example.csv» с содержимым:
nameage
| John | 25 |
| Jane | 30 |
-
- Напишите следующий код, чтобы считать этот список из файла:import csvwith open(«example.csv», «r») as file:
reader = csv.reader(file)
header = next(reader)
lines = list(reader)
print(header)
print(lines)
- Запустите код и вы получите следующий вывод:
- Напишите следующий код, чтобы считать этот список из файла:import csvwith open(«example.csv», «r») as file:
[‘name’, ‘age’]
[[‘John’, ’25’], [‘Jane’, ’30’]]
Пример 3:
-
- Создайте файл «example.json» с содержимым:
{«fruits»: [«apple», «banana», «orange»]}
-
- Напишите следующий код, чтобы считать этот список из файла:import jsonwith open(«example.json», «r») as file:
data = json.load(file)
fruits = data[«fruits»]
print(fruits)
- Запустите код и вы получите следующий вывод:
- Напишите следующий код, чтобы считать этот список из файла:import jsonwith open(«example.json», «r») as file:
[‘apple’, ‘banana’, ‘orange’]
При правильном использовании, наши примеры помогут вам легко считывать списки из файлов в Python. Не забывайте обрабатывать ошибки и проверять правильность формата файла, прежде чем продолжать работу.



